🇧🇷 PT-BR
Pixiv Encyclopedia Viewer History Extractor
![]()
![]()
![]()
🇺🇸 English | 🇮🇳 हिंदी | 🇯🇵 日本語 | 🇨🇳 简体中文 | 🇪🇸 Español | 🇧🇷 Português (Brasil) | 🇰🇷 한국어 | 🇩🇪 Deutsch | 🇫🇷 Français
Uma ferramenta de extração para Pixiv Encyclopedia Viewer Count History
README em japonês
A versão em japonês está aqui: README.ja.md.
Visão geral
Extraia dados diários do histórico de visualizações de um artigo da Pixiv Encyclopedia (pixiv百科事典).
O histórico de visualizações da Pixiv Encyclopedia é um bom dataset de séries temporais do mundo real.
Ele costuma mostrar:
- Sazonalidade semanal (weekday vs weekend traffic)
- Spikes ocasionais causados por events ou social media buzz
Você pode usar o CSV extraído como sample data para:
- Time-series visualization e smoothing
- Seasonal decomposition
- Forecasting models (ARIMA, Prophet, etc.)
⚠️ Tool não oficial
Este project não é afiliado à Pixiv nem endorsed por ela.
Siga Pixiv’s Terms of Use e robots.txt ao usar este script.
Recursos
- Fetch diretamente da Pixiv Encyclopedia por article title (e.g.,
"ブルーアーカイブ") - Ou leitura a partir de um local HTML file
- Output de JSON Lines para stdout
(um{"date": "...","count": ...}por linha) - CSV export opcional via
--csv output.csv
Requisitos
- Python 3.9+
- Dependencies:
requestsbeautifulsoup4
Uso
0. Criar virtual environment
python3 -m venv env
source env/bin/activate
pip install -r requirements.txt
1. Fetch por article title
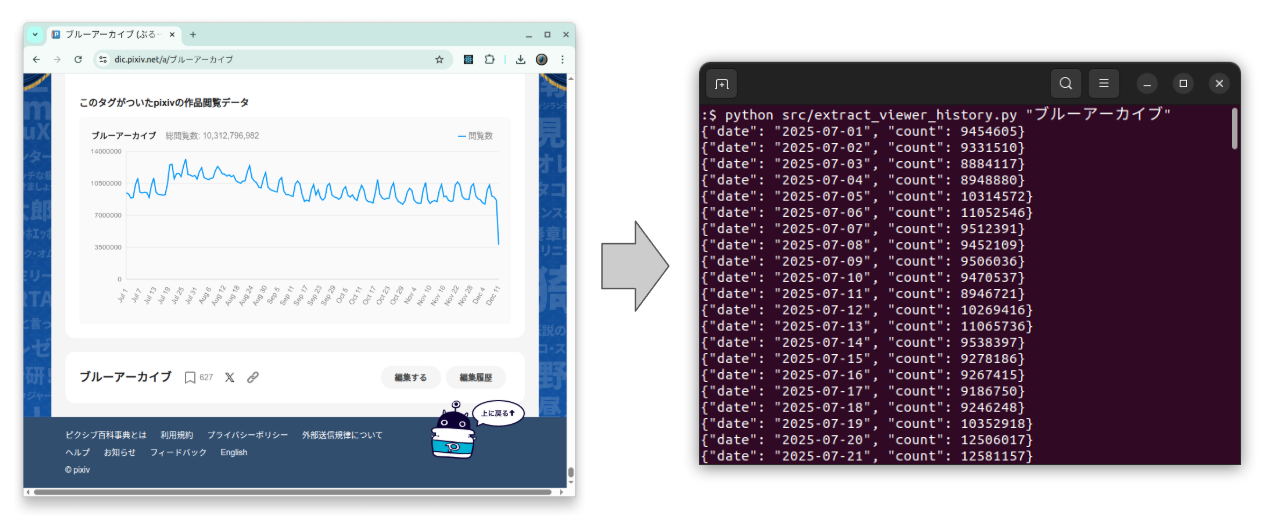
python src/extract_viewer_history.py "ブルーアーカイブ"
Isso irá:
- Baixar
https://dic.pixiv.net/a/ブルーアーカイブ - Fazer parse do embedded JSON
- Fazer print de um JSON object por linha em stdout:
{"date": "2025-07-01", "count": 9454605}
{"date": "2025-07-02", "count": 9331510}
{"date": "2025-07-03", "count": 8884117}
...
Você pode redirecionar isso para um file:
python src/extract_viewer_history.py "ブルーアーカイブ" > ブルーアーカイブ.jsonl
2. Export as CSV
Use a option --csv para escrever um CSV file enquanto ainda imprime JSON em stdout:
python src/extract_viewer_history.py "ブルーアーカイブ" --csv ブルーアーカイブ.csv
Exemplo de CSV content:
date,count
2025-07-01,9454605
2025-07-02,9331510
2025-07-03,8884117
...
3. Usar um local HTML file
Se você já salvou o article HTML:
python src/extract_viewer_history.py ブルーアーカイブ.html
python src/extract_viewer_history.py ブルーアーカイブ.html --csv ブルーアーカイブ.csv
O script detectará que ブルーアーカイブ.html é um file e fará parse dele em vez de fazer fetch da web.
4. Test
pip install -r requirements.test.txt
pytest
5. Deactivate environment
deactivate
Notes / Limitations
- Nenhum rate limiting foi implementado; por favor:
- Use com responsabilidade
- Evite enviar muitas requests em um curto período
- Este é um utility script simples, destinado principalmente a personal analysis ou research.
License
- Apache License 2.0