🇮🇳 हिन्दी
Pixiv Encyclopedia Viewer History Extractor
![]()
![]()
![]()
🇺🇸 English | 🇮🇳 हिंदी | 🇯🇵 日本語 | 🇨🇳 简体中文 | 🇪🇸 Español | 🇧🇷 Português (Brasil) | 🇰🇷 한국어 | 🇩🇪 Deutsch | 🇫🇷 Français
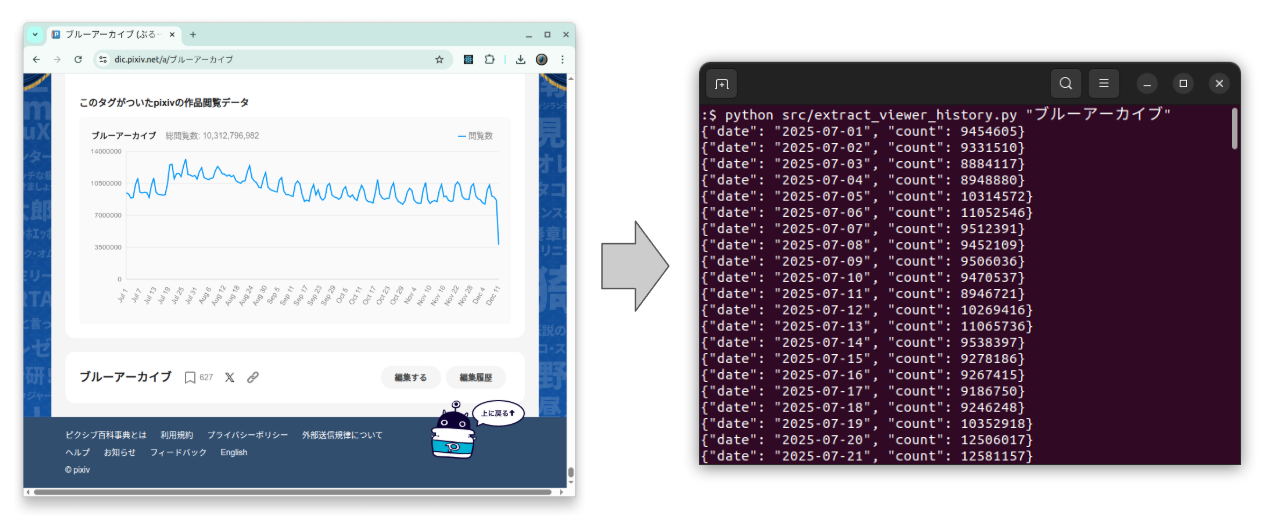
Pixiv Encyclopedia Viewer Count History के लिए निष्कर्षण उपकरण
जापानी README
जापानी संस्करण यहाँ है README.ja.md.
अवलोकन
Pixiv Encyclopedia (pixiv百科事典) के किसी article से दैनिक view history data निकालें।
Pixiv Encyclopedia viewer history एक उपयोगी वास्तविक समय-श्रृंखला dataset है।
यह अक्सर दिखाता है:
- साप्ताहिक seasonality (weekday vs weekend traffic)
- events या social media buzz के कारण कभी-कभी होने वाले spikes
निकाले गए CSV को आप sample data के रूप में उपयोग कर सकते हैं:
- Time-series visualization और smoothing
- Seasonal decomposition
- Forecasting models (ARIMA, Prophet, etc.)
⚠️ अनौपचारिक tool
यह project Pixiv से संबद्ध नहीं है और न ही Pixiv द्वारा endorsed है।
इस script का उपयोग करते समय कृपया Pixiv’s Terms of Use और robots.txt का पालन करें।
विशेषताएँ
- Pixiv Encyclopedia से सीधे article title (e.g.,
"ブルーアーカイブ") द्वारा fetch करें - या किसी local HTML file से पढ़ें
- stdout पर JSON Lines output करें
(हर line में एक{"date": "...","count": ...}) --csv output.csvके माध्यम से वैकल्पिक CSV export
आवश्यकताएँ
- Python 3.9+
- Dependencies:
requestsbeautifulsoup4
उपयोग
0. virtual environment बनाएँ
python3 -m venv env
source env/bin/activate
pip install -r requirements.txt
1. article title से fetch करें
python src/extract_viewer_history.py "ブルーアーカイブ"
यह करेगा:
https://dic.pixiv.net/a/ブルーアーカイブडाउनलोड करेगा- embedded JSON parse करेगा
- stdout पर हर line में एक JSON object print करेगा:
{"date": "2025-07-01", "count": 9454605}
{"date": "2025-07-02", "count": 9331510}
{"date": "2025-07-03", "count": 8884117}
...
आप इसे किसी file में redirect कर सकते हैं:
python src/extract_viewer_history.py "ブルーアーカイブ" > ブルーアーカイブ.jsonl
2. CSV के रूप में export करें
JSON को stdout पर print करते हुए CSV file लिखने के लिए --csv option का उपयोग करें:
python src/extract_viewer_history.py "ブルーアーカイブ" --csv ブルーアーカイブ.csv
CSV content का उदाहरण:
date,count
2025-07-01,9454605
2025-07-02,9331510
2025-07-03,8884117
...
3. local HTML file का उपयोग करें
अगर आपने article HTML पहले से save कर रखा है:
python src/extract_viewer_history.py ブルーアーカイブ.html
python src/extract_viewer_history.py ブルーアーカイブ.html --csv ブルーアーカイブ.csv
Script यह detect करेगा कि ブルーアーカイブ.html एक file है और web से fetch करने के बजाय इसे parse करेगा।
4. Test
pip install -r requirements.test.txt
pytest
5. environment deactivate करें
deactivate
Notes / Limitations
- कोई rate limiting implement नहीं की गई है; कृपया:
- इसे जिम्मेदारी से उपयोग करें
- कम समय में बहुत अधिक requests भेजने से बचें
- यह एक सरल utility script है, जिसका मुख्य उद्देश्य personal analysis या research है।
License
- Apache License 2.0