🇫🇷 Français
Pixiv Encyclopedia Viewer History Extractor
![]()
![]()
![]()
🇺🇸 English | 🇮🇳 हिंदी | 🇯🇵 日本語 | 🇨🇳 简体中文 | 🇪🇸 Español | 🇧🇷 Português (Brasil) | 🇰🇷 한국어 | 🇩🇪 Deutsch | 🇫🇷 Français
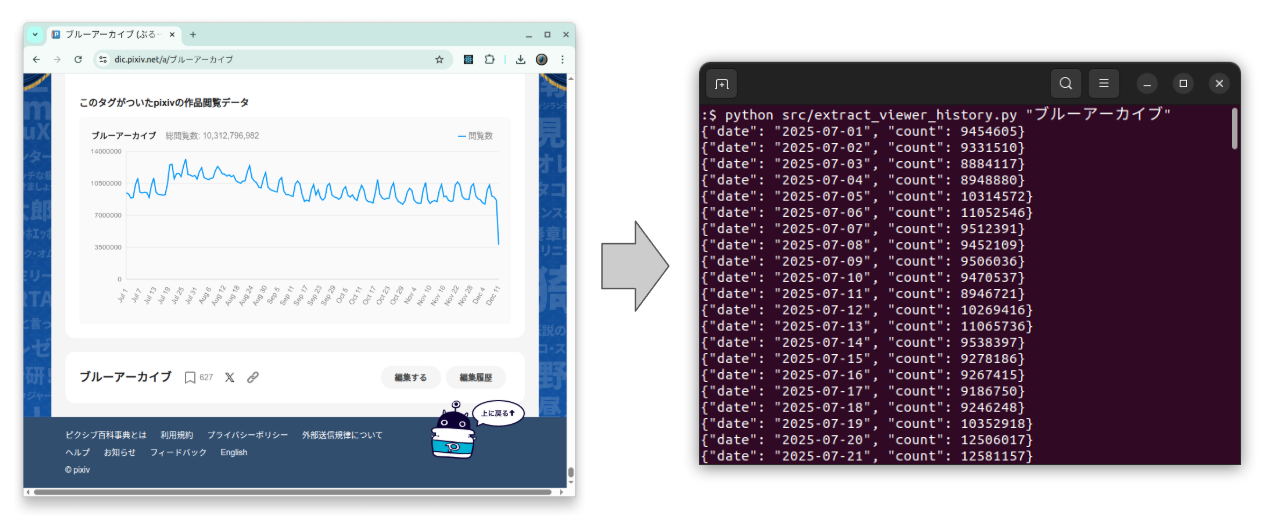
Un outil d’extraction pour Pixiv Encyclopedia Viewer Count History
README en japonais
La version japonaise est disponible ici : README.ja.md.
Vue d’ensemble
Extrayez les données quotidiennes d’historique des vues d’un article de Pixiv Encyclopedia (pixiv百科事典).
L’historique des vues de Pixiv Encyclopedia est un bon dataset de séries temporelles réelles.
Il montre souvent:
- Une seasonality hebdomadaire (weekday vs weekend traffic)
- Des spikes occasionnels causés par des events ou du social media buzz
Vous pouvez utiliser le CSV extrait comme sample data pour:
- Time-series visualization et smoothing
- Seasonal decomposition
- Forecasting models (ARIMA, Prophet, etc.)
⚠️ Tool non officiel
Ce project n’est pas affilié à Pixiv et n’est pas endorsed par Pixiv.
Veuillez respecter Pixiv’s Terms of Use et robots.txt lorsque vous utilisez ce script.
Fonctionnalités
- Fetch directement depuis Pixiv Encyclopedia par article title (e.g.,
"ブルーアーカイブ") - Ou lecture depuis un local HTML file
- Output de JSON Lines vers stdout
(un{"date": "...","count": ...}par ligne) - CSV export optionnel via
--csv output.csv
Prérequis
- Python 3.9+
- Dependencies:
requestsbeautifulsoup4
Utilisation
0. Créer un virtual environment
python3 -m venv env
source env/bin/activate
pip install -r requirements.txt
1. Fetch par article title
python src/extract_viewer_history.py "ブルーアーカイブ"
Cela va:
- Télécharger
https://dic.pixiv.net/a/ブルーアーカイブ - Parser le embedded JSON
- Print un JSON object par ligne vers stdout:
{"date": "2025-07-01", "count": 9454605}
{"date": "2025-07-02", "count": 9331510}
{"date": "2025-07-03", "count": 8884117}
...
Vous pouvez le redirect vers un file:
python src/extract_viewer_history.py "ブルーアーカイブ" > ブルーアーカイブ.jsonl
2. Export as CSV
Utilisez l’option --csv pour écrire un CSV file tout en continuant à imprimer le JSON vers stdout:
python src/extract_viewer_history.py "ブルーアーカイブ" --csv ブルーアーカイブ.csv
Exemple de CSV content:
date,count
2025-07-01,9454605
2025-07-02,9331510
2025-07-03,8884117
...
3. Utiliser un local HTML file
Si vous avez déjà enregistré le article HTML:
python src/extract_viewer_history.py ブルーアーカイブ.html
python src/extract_viewer_history.py ブルーアーカイブ.html --csv ブルーアーカイブ.csv
Le script détectera que ブルーアーカイブ.html est un file et le parsera au lieu de le fetch depuis le web.
4. Test
pip install -r requirements.test.txt
pytest
5. Deactivate environment
deactivate
Notes / Limitations
- Aucun rate limiting n’est implémenté; veuillez:
- L’utiliser de manière responsable
- Éviter d’envoyer de nombreuses requests en peu de temps
- Il s’agit d’un utility script simple, principalement destiné à personal analysis ou research.
License
- Apache License 2.0